Research Highlights
The iGyro research team has created several working prototypes and interactive demos, which can be viewed below.
In the digital age, where echo chambers on social media and news platforms increasingly shape public opinion, there is a growing need for tools that present news consumers with a broad spectrum of perspectives.
Research Team: Peng Qi, Zehong Yan, Wynne Hsu, Mong Li Lee

Misinformation is a prevalent societal issue due to its potential high risks. Out-of-context (OOC) misinformation, where authentic images are repurposed with false text, is one of the easiest and most effective ways to mislead audiences.
We introduce SNIFFER, a novel multimodal large language model specifically engineered for OOC misinformation detection and explanation. Learn more about our project and demo here.
Research Team: Liangming Pan, Xinyuan Lu, Min-Yen Kan, Preslav Nakov
Fact-checking real-world claims often requires complex, multi-step reasoning due to the absence of direct evidence to support or refute them. However, existing fact-checking systems often lack transparency in their decision-making, making it challenging for users to comprehend their reasoning process.
To address this, we propose the Question-guided Multihop Fact-Checking (QACheck) system, which guides the model’s reasoning process by asking a series of questions critical for verifying a claim.
QACheck has five key modules: a claim verifier, a question generator, a question answering module, a QA validator, and a reasoner. Users can input a claim into QACheck, which then predicts its veracity and provides a comprehensive report detailing its reasoning process, guided by a sequence of (question, answer) pairs. QACheck also provides the source of evidence supporting each question, fostering a transparent, explainable, and user-friendly fact-checking process.
- Pan, L., Lu, X., Kan, M.Y., and Nakov, P. (2023). QACheck: A Demonstration System for Question-Guided Multi-hop Fact-Checking. The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Authors: Liangming Pan, Xinyuan Lu, Min-Yen Kan, Preslav Nakov.
Research Team: Simon Chesterman*
*Special thanks to Jiang Yu Hang, Shireen Lee, Elizabeth Ong, Amelie Roediger, Clarie Sng, and Sripratak Thanakorn for invaluable research assistance. Thanks also to Eka Nugraha Putra, Araz Taeihagh, and Audrey Yue for comments. Data visualizations created by Kai Xin Soh.
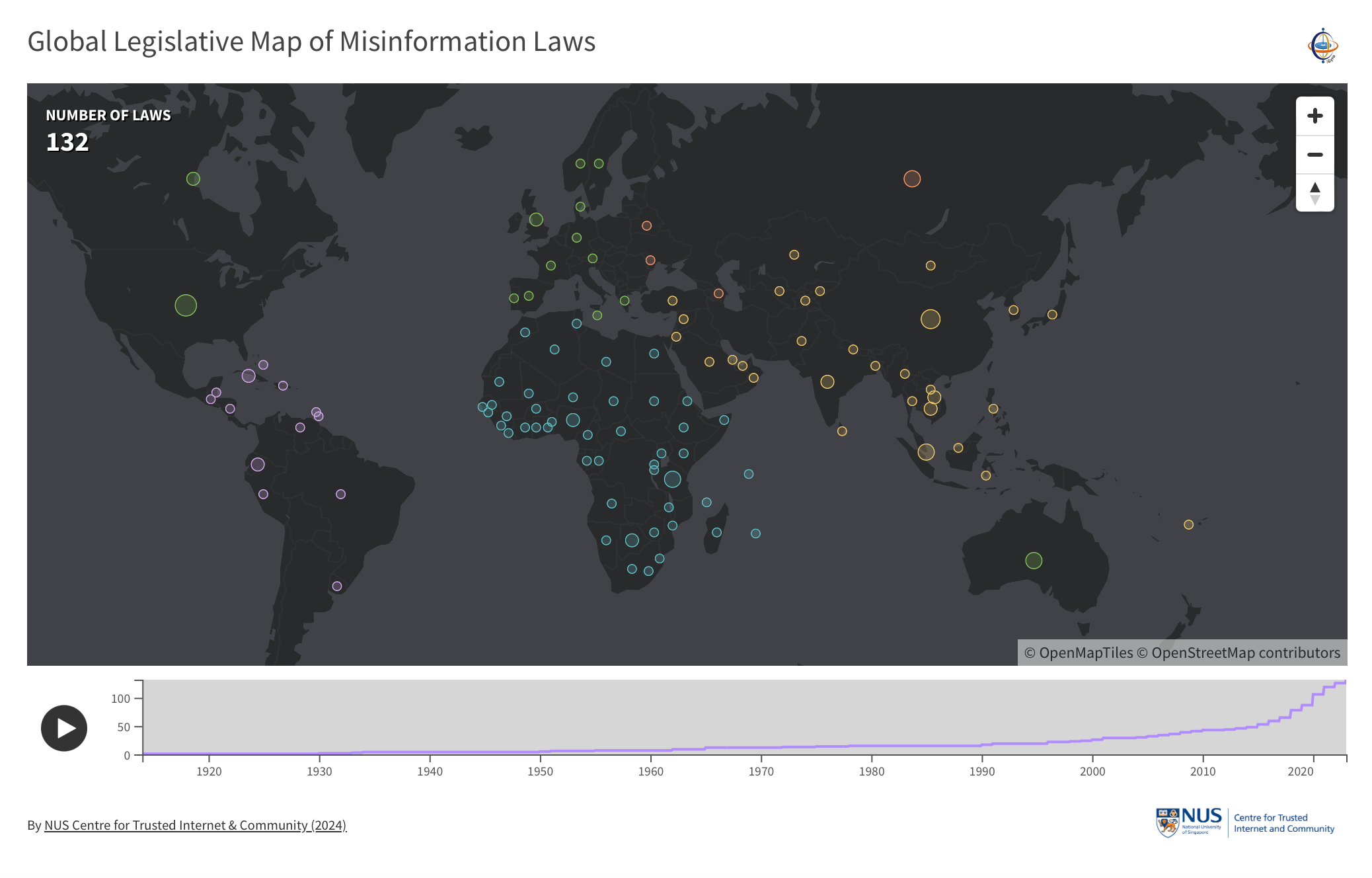
Mapping out the global landscape of legislative movements on 'fake news' and misinformation, we show how laws enacted to tackle misinformation, disinformation, and 'mal-information' around the world have evolved over the past two decades from 1995 to 2023.
In particular, laws tended to be introduced first in countries that were less free (in terms of civil liberties), such as African and Asian countries. More recently, Asian states are responsible for a significant increase in laws and have tended to grant greater powers to governments. Despite early reservations, the growth in such laws is now steepest in Western states, such as the United States, Canada, and the European Union. View our interactive map and learn more about our project here. Download the iGYRO legislative database here.
Research Team: Audrey Yue, Natalie Pang, Renwen Zhang, Jun Yu, Renae Loh
*Special thanks to our collaborators, Prof. Lim Ee Peng (SMU), Dr. Yuhyun Park (DQ Institute), and stakeholders from various government agencies. Thanks also to our researchers for their valuable contributions.
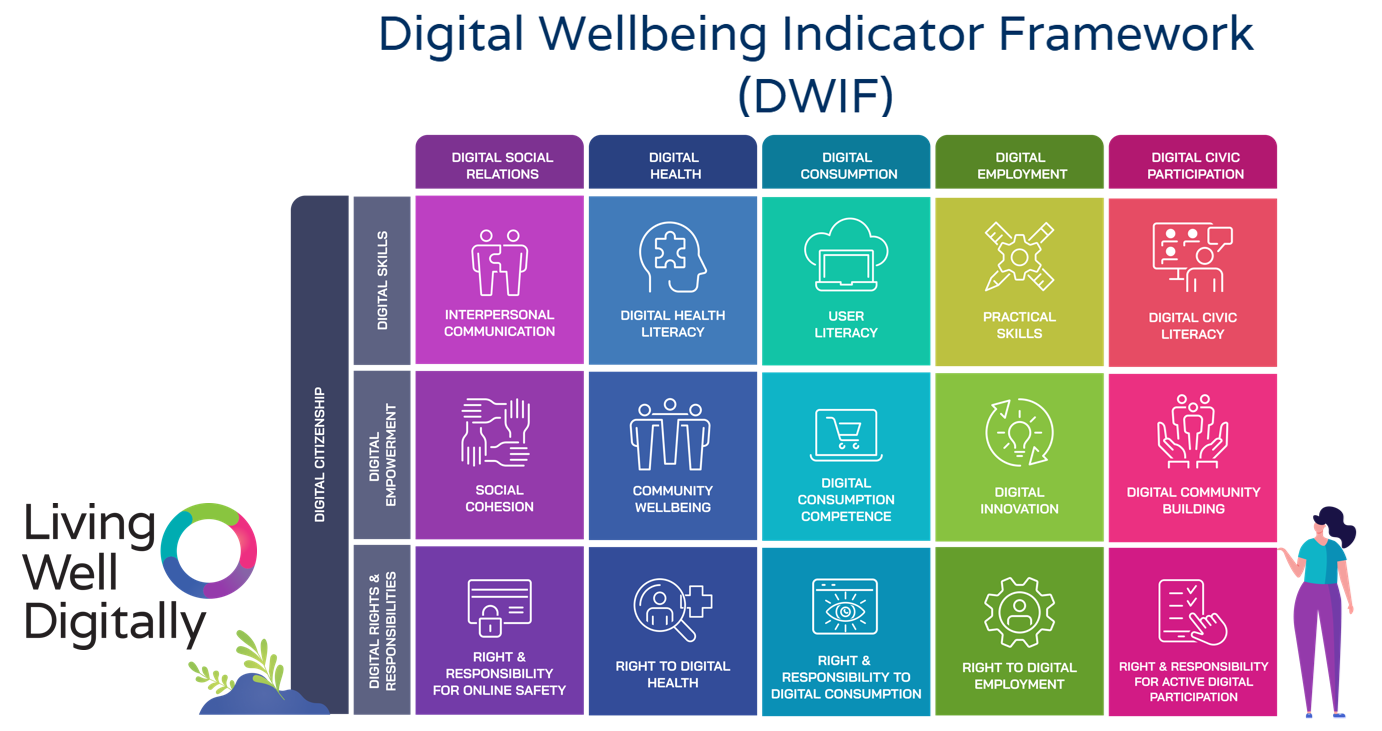
We partnered with DQ Institute to launch the Living Well Digitally web platform and assessment tool, enabling individuals to enhance their digital wellbeing in everyday life. This project aims to redefine wellbeing in the digital age through the development and validation of an original Digital Wellbeing Indicator Framework (DWIF). The DWIF will also form the basis for the development of the digital information resilience framework.
The DWIF has been adopted by the Infocomm Media Development Authority (IMDA) as its official framework for evaluating digital wellness. In collaboration with the National Library Board (NLB), we have developed public resources to promote digital wellbeing, including an educational learning package, an animated explainer video, and our inaugural Introduction to Digital Wellbeing Workshop held at Woodlands Regional Library.
Our international collaborations continue to strengthen and expand the framework. We are working with Fudan University to refine the DWIF and generate insights into digital wellbeing across cities in China. Additionally, we are partnering National Yang Ming Chiao Tung University to implement the DWIF questionnaire in Taiwan.
- Yue, A., Pang, N., Torres, F., & Mambra, S. (2021). Developing an indicator framework for digital wellbeing: Perspectives from digital citizenship.
- Li, H., Zhang, R., Lee, YC., Kraut, R.E. & Mohr, D.C. (2023). Systematic review and meta-analysis of AI-based conversational agents for promoting mental health and well-being. npj Digital Medicine.
- Zhu, Z., Liu, S., & Zhang, R. (2023). Examining the persuasive effects of health communication in short videos: a systematic review. Journal of Medical Internet Research.
- Yue, Z., Zhang, R., & Xiao, J. (2023). Social media use, perceived social support, and well-being: Evidence from two waves of surveys peri- and post-COVID-19 lockdown. Journal of Social and Personal Relationships.
- Yue, Z., Lee, D., Xiao, J. & Zhang, R. (2023). Social media use, psychological well-being and physical health during lockdown. Information, Communication & Society, 26 (7), 1452-1469.
- Luo, X., & Zhang, R. (2024). Decoding the gendered design and (dis)affordances of face-editing technologies in China. International Journal of Human-Computer Studies.
- Loh, R. S. M., Kraaykamp, G., & van Hek, M. (2025). Plugging in at school: Do schools nurture digital skills and narrow digital skills inequality?. Computers & Education, 226, 105195.
Author: Simon Chesterman
Summary
This article presents a comprehensive and empirically grounded legal analysis of 151 national laws introduced from 1995 to 2023 to address online mis-, dis-, and mal-information (MDM). Drawing on a novel global dataset, Prof. Simon Chesterman highlights that legislative responses began in less free and lower-income countries but are now rapidly expanding across Western democracies.
The impetus includes rising reliance on social media, the infodemic during COVID-19, and the disruptive potential of genAI like ChatGPT and deepfakes, especially in a globally election-heavy year in 2024.
The paper distinguishes between misinformation (false but not malicious), disinformation (deliberately false), and mal-information (factual but harmful), advocating nuanced regulation. Laws increasingly focus on national security, public health, and electoral integrity. While balancing free speech remains complex, the article argues that regulating “lawful but awful” content is no longer optional but essential for democratic resilience and societal trust in the digital age.
Adding the following supporting image for social media content:

Source: Prof. Chesterman's paper, page 5.
Key Findings
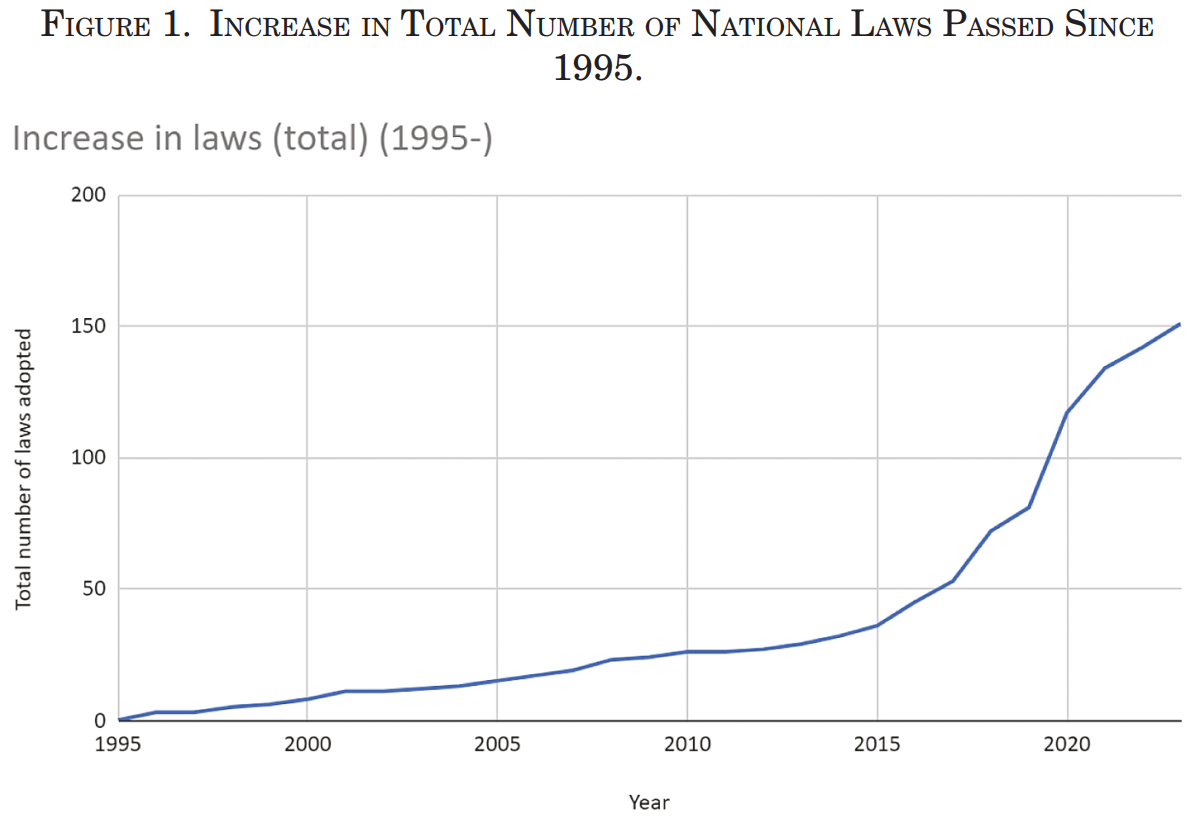
- The number of MDM-related laws tripled between 2016 and 2023.The following image supports the first key finding:
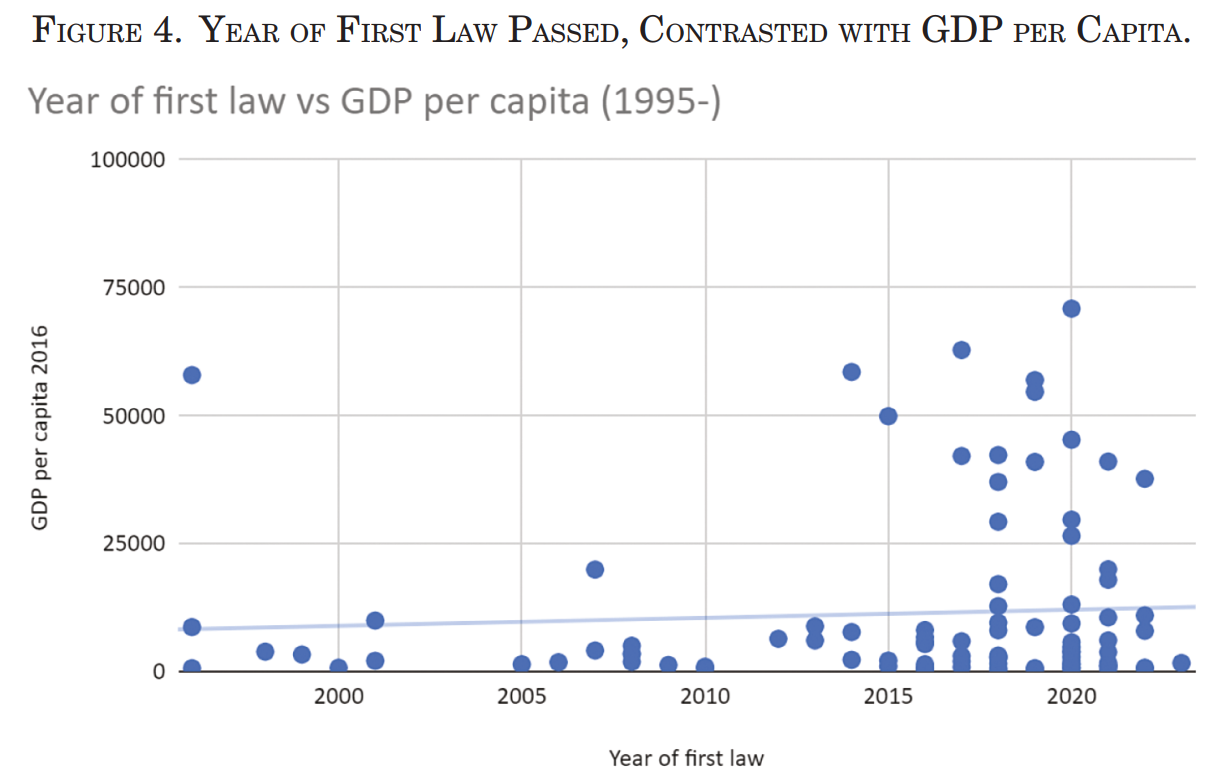
- Early adopters: countries with limited civil liberties and lower GDP per capita. The following image supports the second key finding:
- Legal priorities have shifted from national security to public health (especially post-COVID), and now to AI threats.
- Generative AI and deepfakes have intensified regulatory urgency due to their role in impersonation, electoral interference, and information warfare The following image supports the 3rd and 4th key findings:
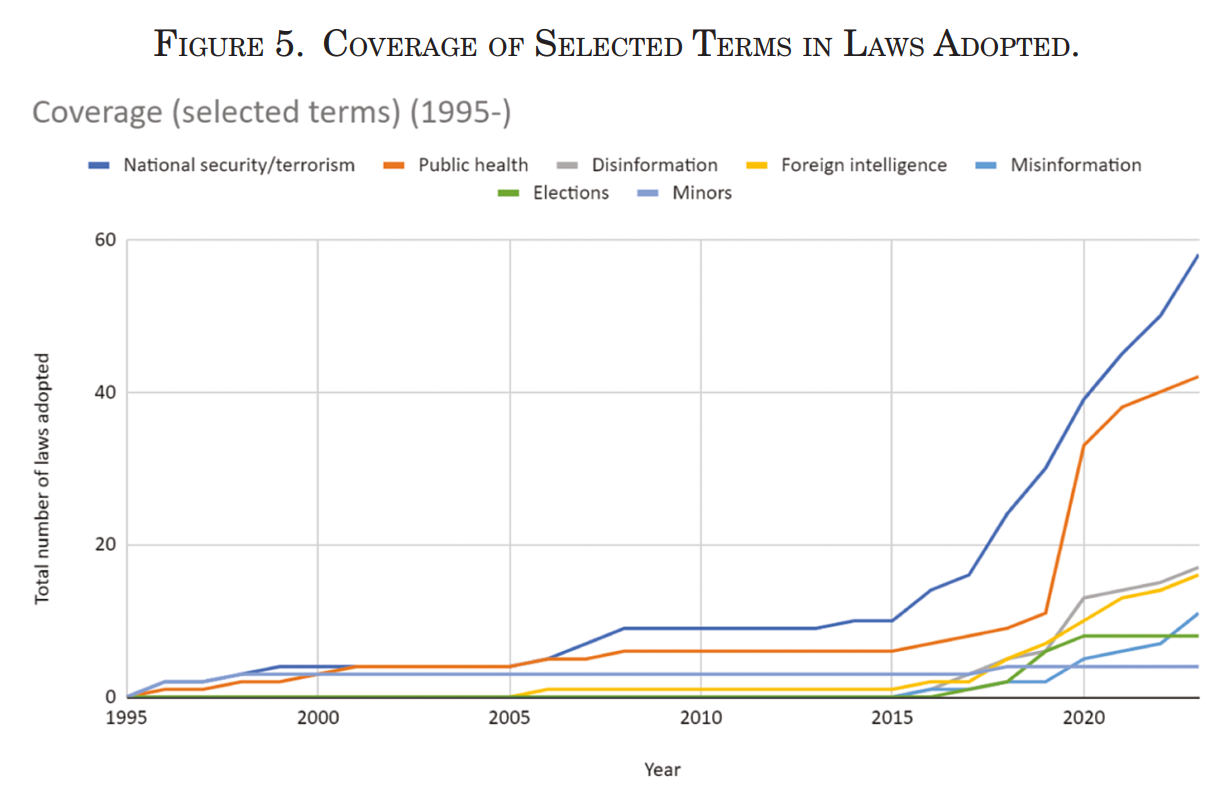
- Legislative emphasis is shifting from mere content regulation to infrastructure, distribution pathways, and platform accountability. The following image supports the last key finding:
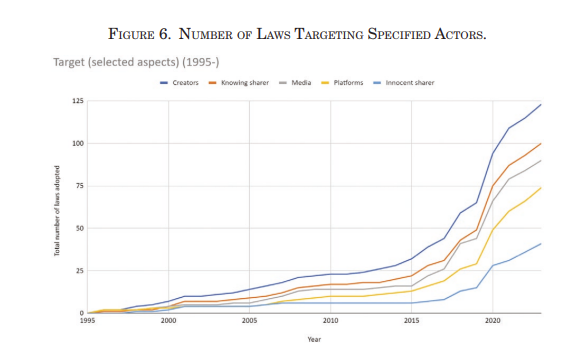
- Chesterman, S. (2025). Lawful but Awful: Evolving Legislative Responses to Address Online Misinformation, Disinformation, and Mal-Information in the Age of Generative AI. The American Journal of Comparative Law.
- View the infographic.
- Listen to the podcast with Prof. Chesterman and Dr. Fakhar Abbas as the host.
Authors: Fakhar Abbas and Araz Taeihagh
Summary
In an era where AI-generated media is blurring the lines between truth and manipulation, this peer-reviewed study offers the most comprehensive systematic review on deepfake generation and detection using artificial intelligence. Drawing on over 200 rigorously screened studies, the paper examines how cutting-edge AI techniques, including GANs, autoencoders, diffusion models, and hybrid transformer-based models, are utilized to both create hyper-realistic synthetic media and detect manipulated content across video, image, and audio domains.
The study presents a comprehensive taxonomy of deepfake techniques, encompassing face-swapping, reenactment, and attribute manipulation, and assesses leading detection tools such as StyleGAN2, MND-GAN, and LE-GAN. It further identifies persistent challenges in detection accuracy, particularly the limited effectiveness of widely used commercial APIs, such as Microsoft Azure and Amazon Rekognition. With its methodological rigor and cross-disciplinary insights, this review is a foundational reference for AI researchers, media technologists, policymakers, and platform stakeholders working at the intersection of synthetic media, detection technologies, and information integrity.
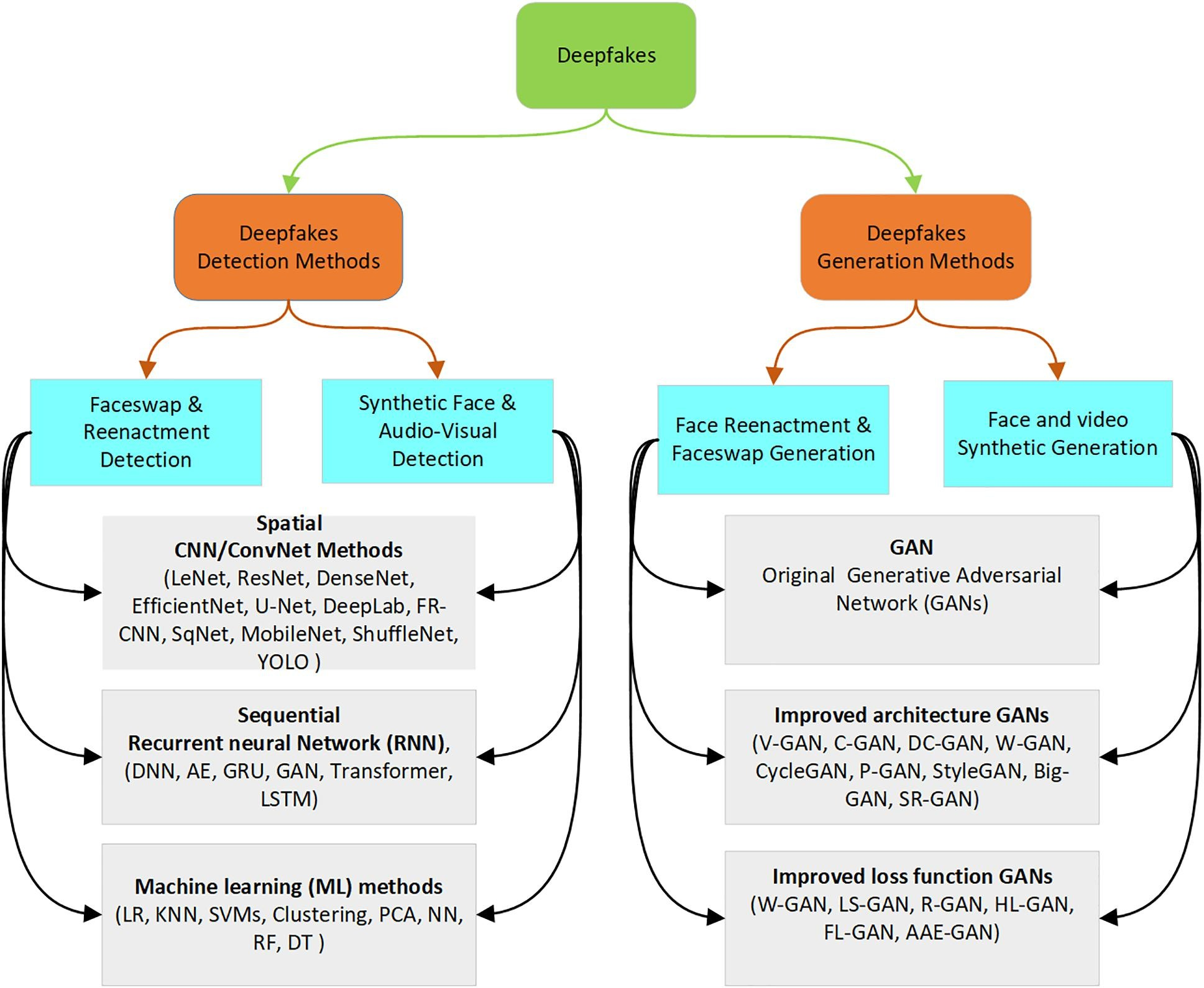
Fig 1: Taxonomy of Deepfake Detection and Generation approaches
Source: Dr. Abbas' paper, page 8.
Key Findings
- First systematic review uniting both deepfake generation and detection methods across all media types (video, image, audio).
- Commercial AI tools, such as Microsoft Azure and Amazon Rekognition, are highly susceptible to vulnerabilities. Up to 78% of them fail to detect deepfakes.
- StyleGAN2, SC-GAN, LE-GAN, and hybrid models have dominated recent innovations, yet they struggle with real-time robustness and generalizability.
- Policy discussions lag behind technical advancement; current regulations lack enforceability and cross-platform standards.
- The study proposes a cross-disciplinary research and policy roadmap that integrates AI, computational forensics, and media governance.
The following image supports the key finding and policy recommendation.
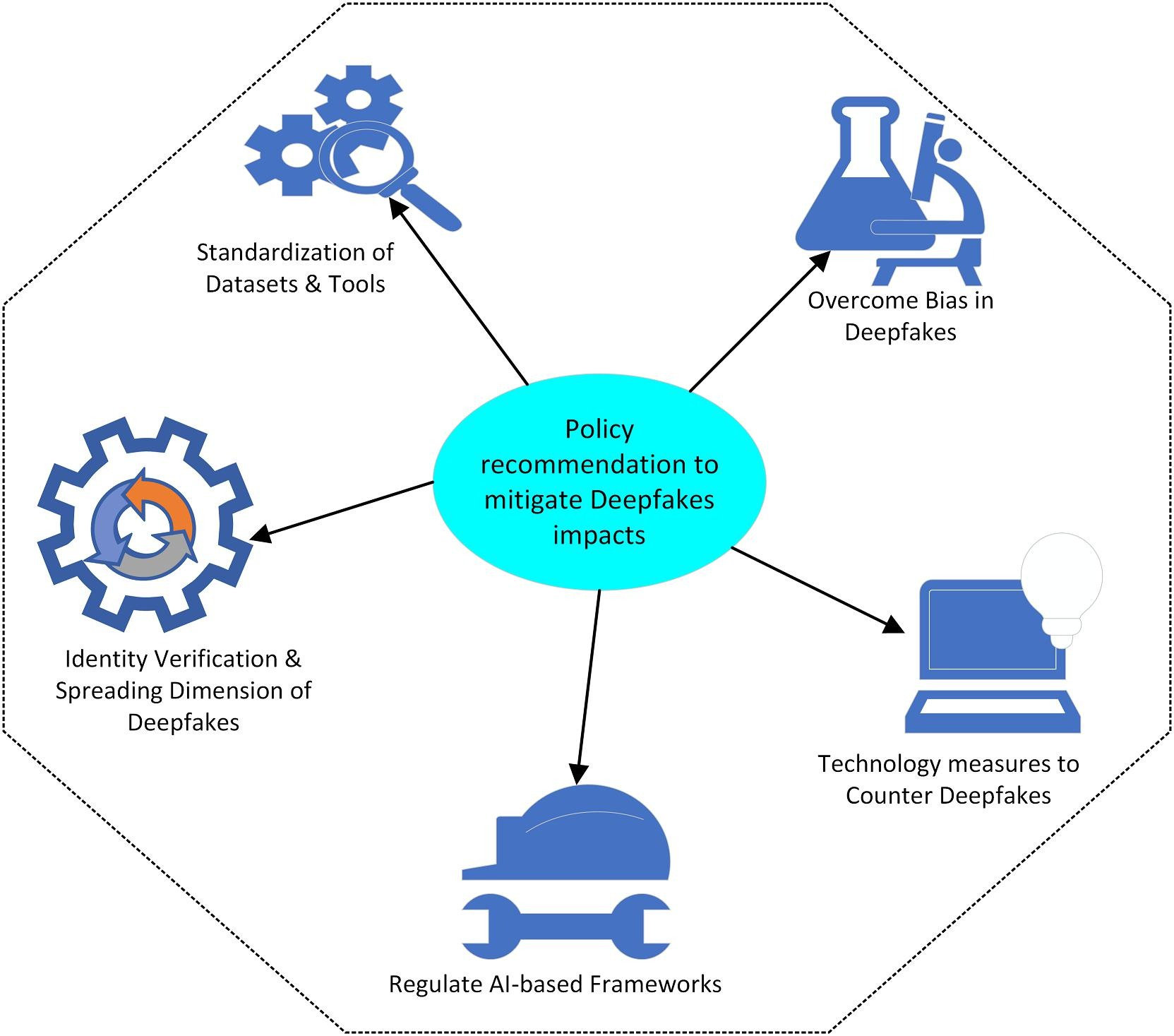
Fig 1: Taxonomy of Deepfake Detection and Generation approaches
Source: Dr. Abbas' paper, page 8.
- Abbas, F. & Taeihagh, A. (2024). Unmasking Deepfakes: A Systematic Review of Deepfake Detection and Generation Techniques Using Artificial Intelligence. Expert Systems with Applications.
- View the poster.
- View the presentation slides.